The Architecture & Science Behind Flow PPU
Years of research.
Rethinking parallel performance.
Flow Computing®’s architecture is based on more than 30 years of scientific research in parallel computing, memory systems, and processor design. This foundation was established by CTO, Chief Architect, and Co-Founder, Martti Forsell, PhD, Docent, through his academic and applied work at the University of Joensuu and VTT Technical Research Centre of Finland.
With the help of colleagues, the scientific community, and over 160 scientific publications and contributions to key developments in the field, Forsell’s research crystallized into the design of the Parallel Processing Unit® (Flow PPU), including its core innovations: highly efficient and interoperable versions of the Emulated Shared Memory (ESM) architecture, and Thick Control Flow (TCF) model, with a natural and easy-to-use parallel programming methodology.
Research foundations
The theoretical foundations of the research cover key models of parallel and sequential computation (e.g., PRAM [Fortune78], BSP [Valiant90], RAM [Cook73]), theory of sequential and parallel architectures [Forsell02a], shared memory and its emulation [Forsell94, Ranade91, Forsell02b], interconnection networks, cache coherency alternatives, compiler techniques for explicit parallelism, theory of parallel algorithms, and architectural feasibility studies across both hardware and system integration. More practical aspects include simulation environments and empirical evaluation of performance, interconnect designs, resource usage and utilization, and throughput and scalability, as well as sophisticated constructs for expressing parallelism in programming languages and methods for migrating legacy programs [Keller01].
One of the cornerstone achievements, the Thick Control Flow architecture, has been shown to address the requirements for efficient general purpose parallel computing to radically boost performance and enable near-linear scalability. The architecture is also designed to simplify parallel software development, eliminating the need for extensive hardware-specific tuning and manual memory partitioning.
Over the past few decades...
Multicore CPUs integrating a number of processor cores on a single chip have substituted sequential processors almost entirely and become the workhorses of modern computing devices [Tendler02, Intel06]. This transition happened due to semiconductor technology limitations that have effectively halted exponential clock frequency growth [ITRS03]. The original target and motivation for multicore CPUs was that with C cores, a programmer could either solve C times larger problems at the same time or solve equally sized problems C times faster than its single core counterpart.
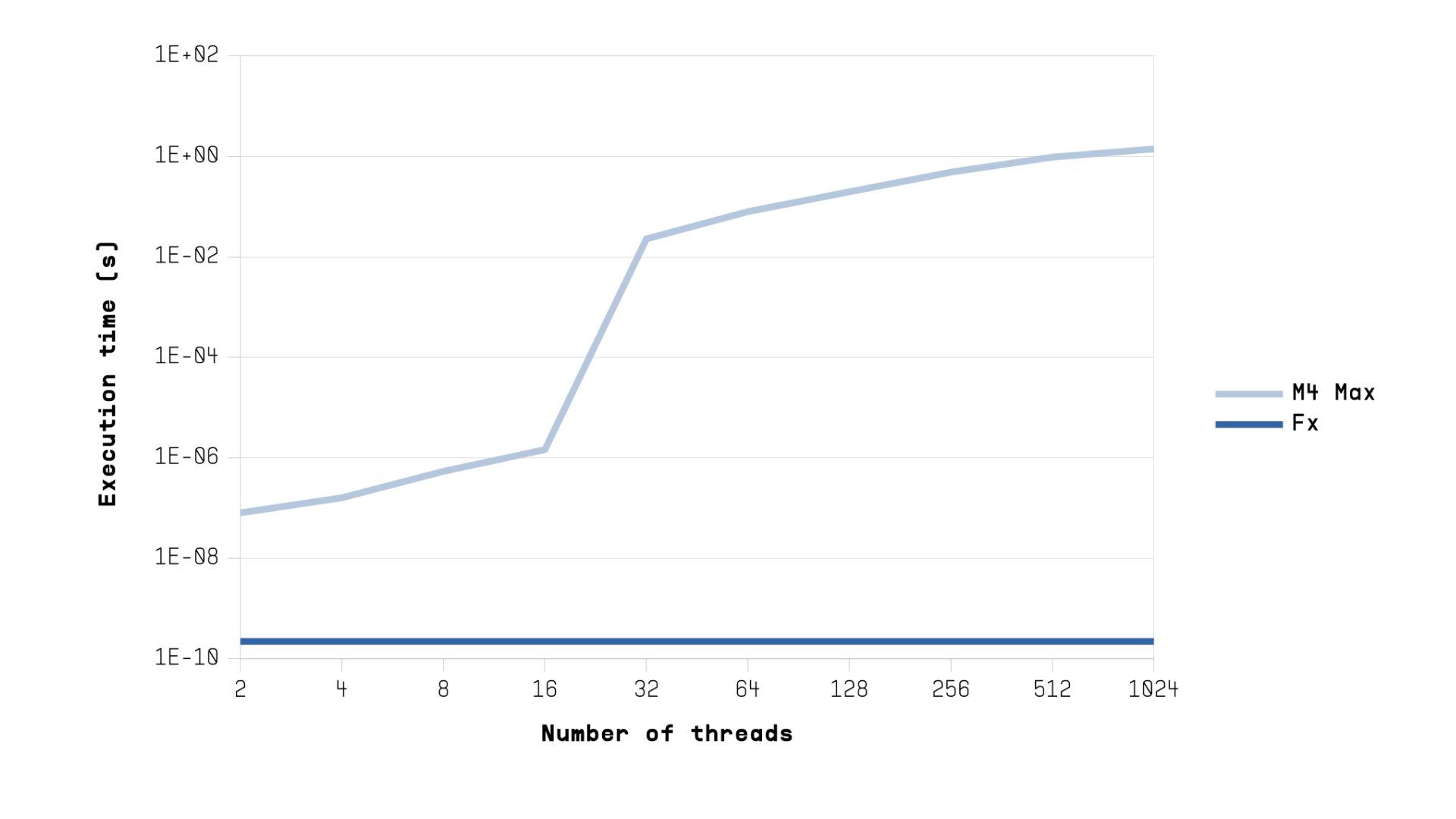
However, most processor architectures have failed to scale performance efficiently with increasing core counts. [Forsell25]
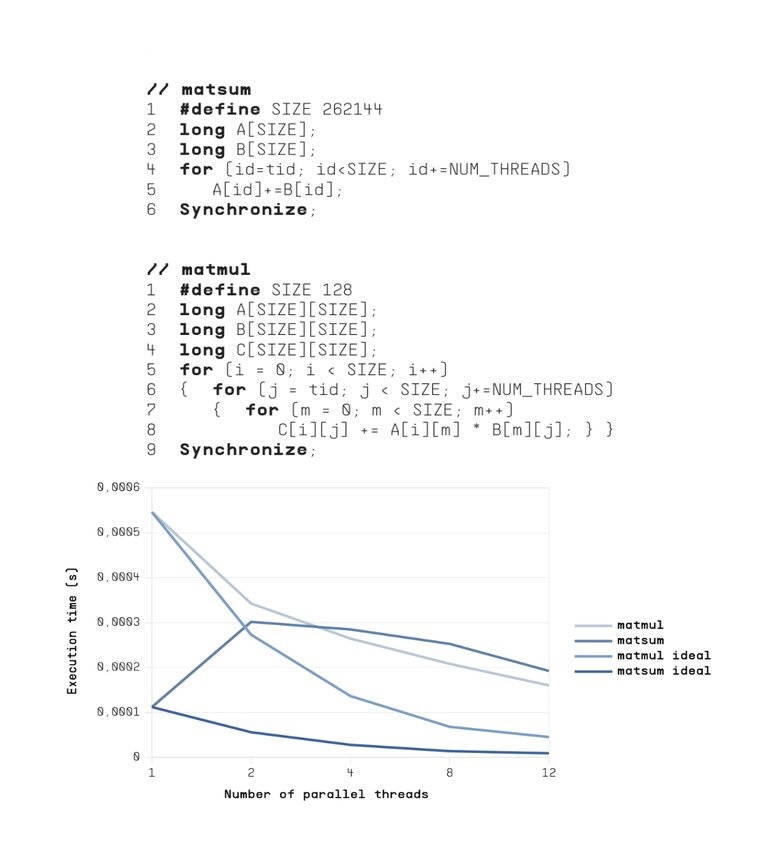
This image shows the measured execution time scaling of matsum and matmul implemented with C/P threads as a function of the number of threads on an Apple M4 Max system compared to ideal scaling of a single threaded execution.
Despite increasing thread counts, performance scales poorly or even degrades, highlighting fundamental limitations in mainstream multicore CPUs (tid=thread identifier, NUM_THREADS=number of parallel threads).
Semiconductor technology limitations
For decades, the semiconductor industry relied on two trends: Moore’s Law, which doubles transistor density every 18-24 months [Moore65], and Dennard scaling, which reduces voltage and current to maintain power efficiency [Dennard74].
But in the late 1990s [Mazke97, Mudge01], these trends began to break down due to physical and thermal constraints. As a result, frequency scaling stalled, and adding more processor cores to a single microchip became the default strategy for performance gains [Tendler02, Intel06]. As the number of cores has grown, the limited physical size of a single silicon chip that can be manufactured has become a problem. Solutions have been searched from chiplet, 3-dimensional through silicon via and wafer-scale integration technologies that introduce further challenges such as higher cost, limited bandwidth, cooling and fault/defect tolerance.
Architectural inefficiencies
Unfortunately, the selected multicore parallel computing approach soon ran into the troubles we are facing today: Simply adding cores introduces new architectural challenges, especially in memory access, synchronization, and software development complexity [Forsell22, Forsell23, Forsell25]. Traditional multicore designs [Culler99], which rely on cache coherence and complex mechanisms to maintain it, are prone to delays caused by inter-core operations, and often require tedious manual tuning to achieve decent parallel performance [Forsell22].
As core counts rise, these issues result in diminished returns [Forsell23, Forsell25]. This is the origin of the parallel computing challenge that Flow’s PPU was designed to solve. Flow PPU is designed to solve the architectural bottlenecks that emerged as semiconductor scaling slowed and parallel processing was left as the only way to increase general purpose computation performance [Jouppi18, Forsell22, Forsell23].
Modern processors face 3 major bottlenecks
- Memory access inefficiencies
- High synchronization overhead
- Poor scalability as core counts increase
These challenges limit the effectiveness of multicore architectures, and significantly increase complexity for software developers [Keller01, Forsell22, Forsell23].
SMP & NUMA issues
Current multicore CPUs utilize the SMP or NUMA organizations:
In Symmetric Multiprocessor (SMP) systems, identical processors with private caches are connected to the main memory via a bus or communication fabric. All memory locations are equidistant from all processors, thus access is symmetric. While this can provide speedup in small systems, memory access unavoidably leads to bottlenecks as the number of cores grows.
In Non-Uniform Memory Access (NUMA) systems, the shared memory is organized so that memory access time depends on memory location [Swan77, Lenoski92]. Depending on distance and on-going traffic, non-local memory accesses have higher latency than local accesses. While NUMA architectures work well if the majority of memory accesses are targeted at local data, performance for non-trivial access patterns is far from optimal [Forsell23, Forsell25].
Except for very old designs, both SMP and NUMA rely on cache coherence protocols to maintain memory consistency across cores, mechanisms that become increasingly expensive and difficult to scale as the number of cores grows [Forsell25].
Parallel programming challenges & system-level bottlenecks
Developing efficient software for traditional multicore systems often requires teams of specialists to manage thread-level parallelism manually, writing low-level synchronization code, tuning for cache and memory system behavior, and dealing with hard-to-reproduce issues related to asynchrony, non-determinism, race conditions, deadlocks, starvation and livelocks [Patterson10, HiPEAC13].
Even small memory access or synchronization issues can lead to significant performance loss or system instability. This complexity slows down development, increases engineering effort, and often results in underutilized hardware, especially in latency-sensitive or real-time environments.
Another dimension of system-level problems is caused by limited memory bandwidth, which slows down multicore processors and GPUs.
Our architecture combines a traditional CPU with a novel Flow PPU.
In order to find a solution to the problems mentioned above, Flow uses a new architecture for parallel parts of the code and an explicitly parallel programming paradigm. The solution employs an improved version of the emulated shared memory architecture and thick control flow abstraction to architecturally and methodologically realize a theoretically strong machine as well as a natural and easy-to-use methodology.
SHARED MEMORY EMULATION
Using shared memory efficiently as a medium of intercommunication is not trivial despite its popularity and conceptual simplicity. While current multicore CPUs provide their programmer with a common memory, using it in the same way as the strong and theoretically elegant Parallel Random Access Machine [Fortune78] is expensive especially in the case of inter-thread dependencies and non-local memory accesses [Forsell22, Forsell23, Forsell25].
To mitigate these issues, processor manufacturers provide traditional multicore systems with hardware-based cache coherence mechanisms to maintain memory consistency across cores, an approach that limits scalability and adds complexity.
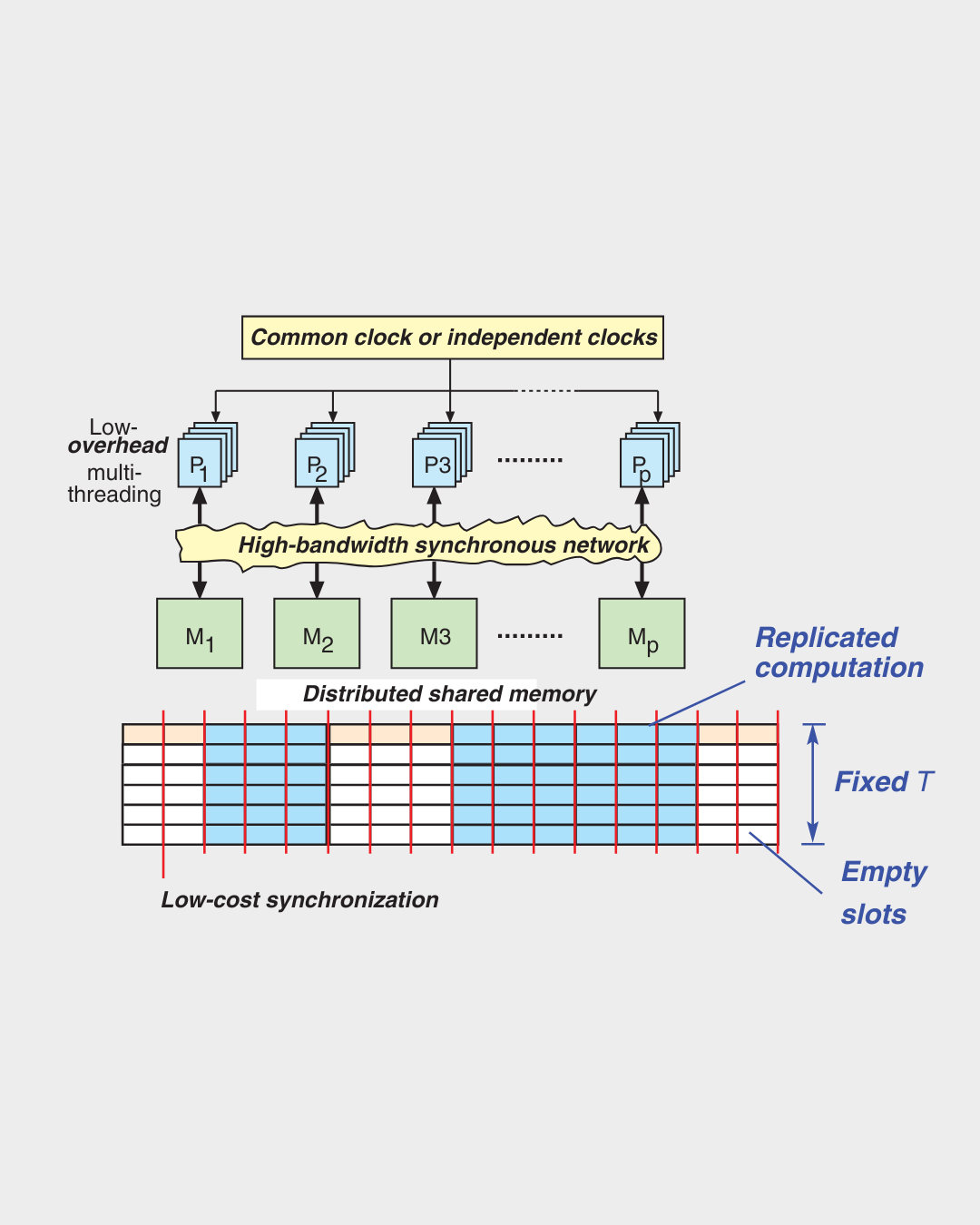
While a direct realization of multiport memory with ideal properties is very expensive [Forsell94], there exist ways to emulate shared memory cost-efficiently: Emulated Shared Memory (ESM) architectures [Ranade91, Keller01, Forsell02b] that eliminate cache coherency problems, provide latency hiding, high memory bandwidth, light-weight synchronization and a simplified programming scheme, eliminating the need for locality maximization and partitioning in memory access (see Figure).
Instead of attempting to minimize the latency of a single operation as a part of sequence of instructions, ESM architectures attempt to organize the execution of operations so that maximal throughput is achieved.
Unfortunately, the academic ESM architectures proposed in the 1990s and 2000s suffer from area and power overheads due to redundant MIMD models [Flynn72], performance issues when the number of threads is low due to the fixed multithreading scheme [Forsell18] and are not capable of providing a method for fluently matching the parallelism to the algorithm in hand [Keller01, Forsell16].
THICK CONTROL FLOW ABSTRACTION
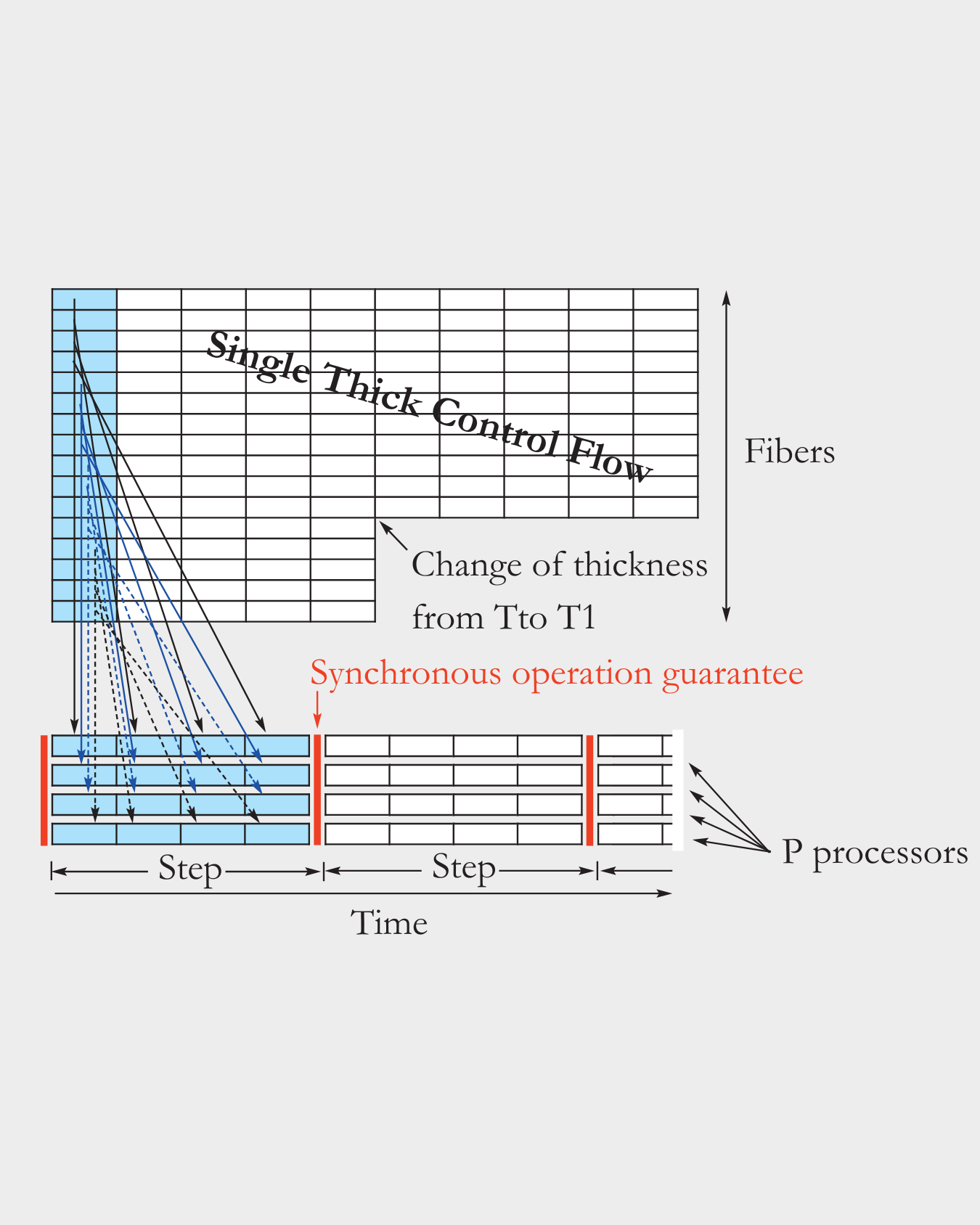
A Thick Control Flow (TCF) is Flow’s programming model designed to streamline parallel task execution [Leppänen11, Forsell13]. It eliminates many of the control-flow inefficiencies seen in traditional pipelines by executing groups of threads (fibers) in a tightly orchestrated fashion. The number of threads, i.e. parallelism, in a TCF is called thickness. Fibers are executed in steps during which all fibers execute a single instruction. A TCF can also be seen as an abstraction that simplifies parallel programming by managing a number of parallel software components with a single control like a vector or thread with data parallelism would do.
TCF supports dynamic, nested parallelism and deterministic thread control, reducing instruction and synchronization overhead while improving scalability and performance predictability [Forsell20, Forsell22]. The fibers within a TCF are executed synchronously with respect to each other leading to a well-defined state of computation, which is a cornerstone for correctness of programs.
With respect to popular Single Instruction Multiple Data (SIMD) and Multiple Instruction Multiple Data (MIMD) models [Flynn72], TCF scheme provides a possibility to gain savings from the homogeneity of computing like the SIMD model does without replicating the resources like the MIMD model does but with a greater flexibility.
The figure on the right shows a TCF architecture conceptually executing the first instruction of 16-fiber TCF assuming the execution would happen in four processors.
HYBRID APPROACH
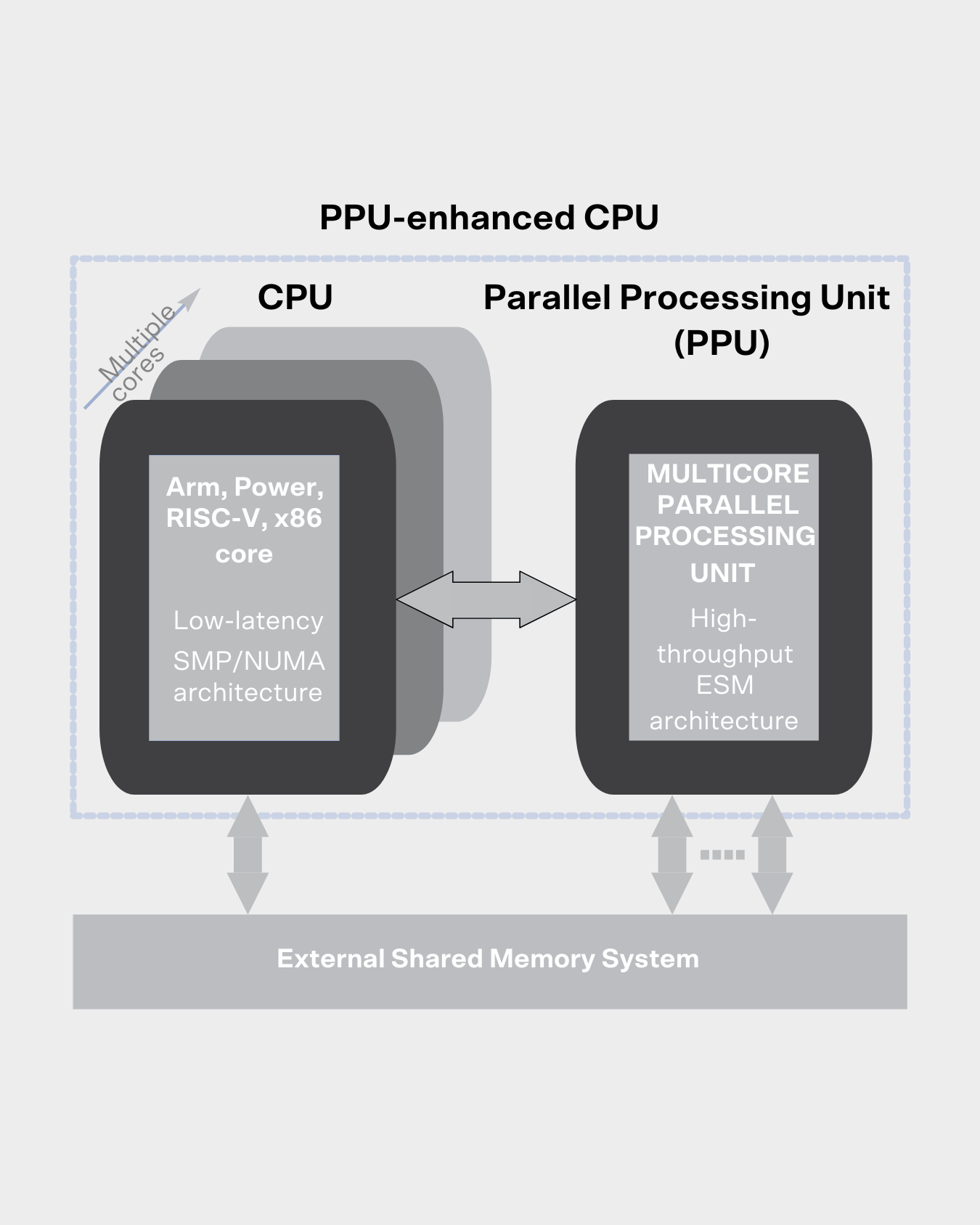
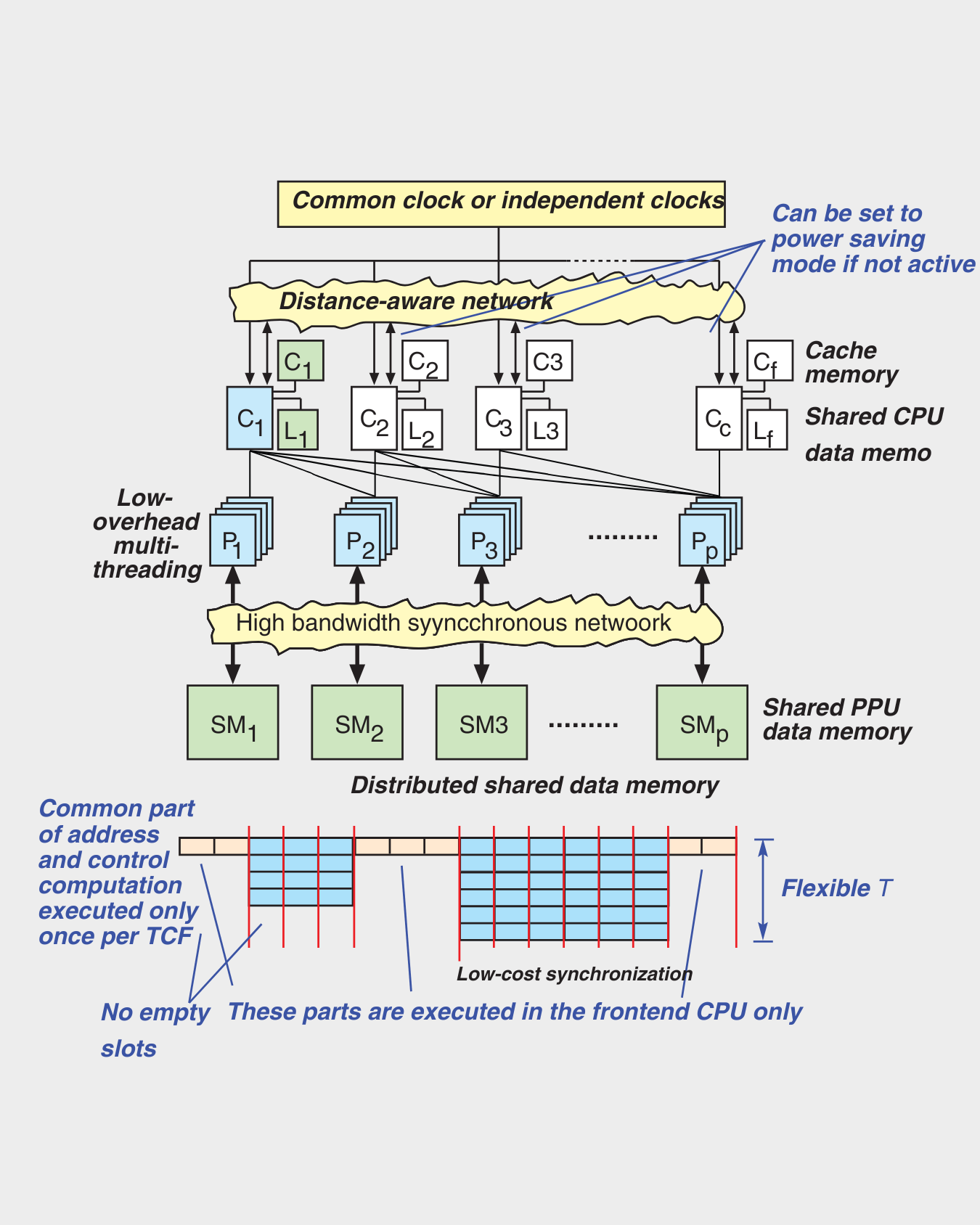
Attempts to solve the problem of early ESM proposals by integrating low-latency and high-throughput executions into a single monolithic architecture indicate that either sequential or parallel execution gets compromised [Forsell18]. Our approach is to integrate dedicated sequential and parallel architectural components into a tightly coupled entity utilizing a Central Processing Unit (CPU) and Flow Parallel Processing Unit (PPU) [Forsell16] (see Figure). In the resulting hybrid architecture, the CPU handles sequential execution, TCF control, and legacy code, while Flow PPU is optimized for high-performance, general-purpose parallel computing, i.e., efficiently executing individual parallel software components. Both architectural units access a unified memory system to allow co-processing, simplify data handling, and minimize the need for explicit synchronization.
This division into sequential and parallel architectural components makes it possible to employ existing and future multicore CPUs by major processor manufacturers only with minor modifications as a part of Flow's system independently of the instruction set. It allows scaling the parallel architecture part independently of the established CPU part.
FLOW ARCHITECTURE
Flow PPU uses a scalable multi-fibered multicore architecture that can be configured at design time for various constellations aimed generally at addressing the performance and programmability issues of current general purpose architectures [Forsell16]. Performance and memory access scalability are supported by exploitation of parallel slackness, providing high enough bandwidth, minimizing synchronization costs and splitting the execution into common and data parallel parts that can be carried out in separate architectural entities optimized for their designated use.
Another advantage is the ability to adjust parallelism according to the needs of the coded algorithm. All this happens by executing other fibers while a fiber is accessing the memory so that even high latencies are tolerated [Forsell22], using the multimesh interconnect, trading slow barrier synchronizations into a synchronization wave that separates the references belonging to consecutive execution steps [Ranade91] and using a CPU to take care of fetching instructions from the memory and executing the common parts of TCFs, such as control of the flow and base address computation and a PPU to handle execution of individual fibers independently of the number of them (see Figure).
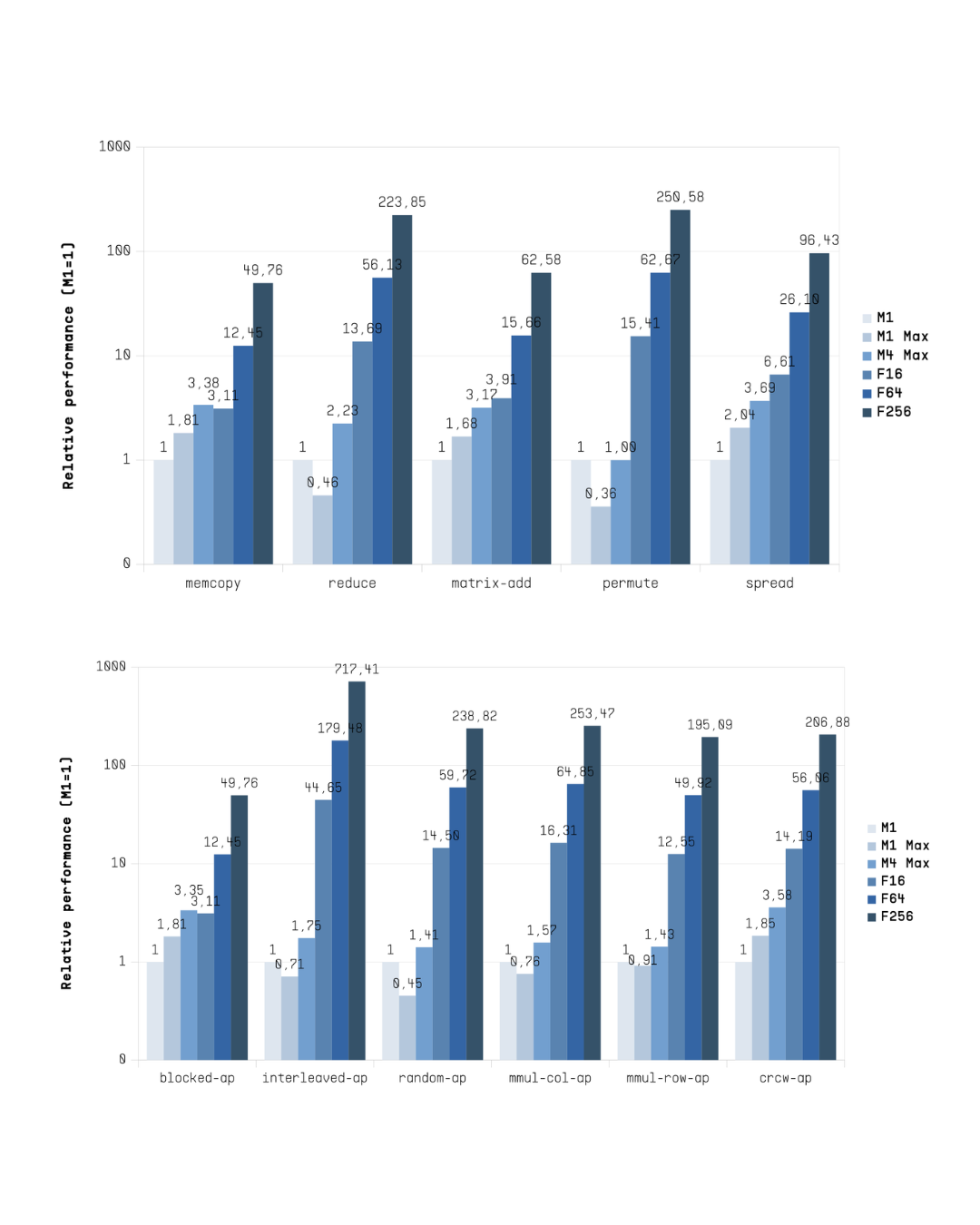
The relative performance of four Flow PPU systems was compared to three Apple M-series CPUs (see Table below) across various parallel compute, synchronization and memory access patterns (see Table below). The results are shown in the bar chart.
In these benchmarks, Flow’s F256 configuration significantly outperformed Apple’s M-series processors, achieving on average 211x, 221x and 105x higher performance in memory access pattern tests wrt. to M1, M1 Max and M4 Max, respectively. Compute patterns show an average speedups that are roughly half of those measured in the memory access comparison.
Flow PPU's performance advantage comes from better toleration of memory system latency, sufficient bandwidth, more cost-efficient synchronization and higher FU utilization. The best speed-ups were measured with non-trivial memory access and compute patterns including inter-fiber dependencies.
Let's look more closely at the PPU performance, software design complexity and benchmarking methodology.
Benchmark methodology
Benchmarks included representative compute- and memory-intensive workloads such as matrix addition, memory-bound access patterns, and synchronization routines implemented as explicitly parallel blocking C/P threads and TCF assembler programs (see Table below). The compared processors include Flow systems with 4, 16, 64 and 256 core Flow PPU and 4+4-core Apple M1, 8+2-core M1 Max and 12+4-core M4 Max (see Table below).

Benchmark integrity is ensured through fair and consistent testing
All tests were run carefully to distinguish different algorithmic styles (maximally parallel, matched parallel and blocking), repeated multiple times in the test program and included the actual payload only, excluding additional SIMD accelerators in all systems, ensuring that caches are hot and waiting long enough to fully ramp up from all possible power saving modes. It was also assumed that our systems would run at the same clock frequency of 4.52 GHz as the most recent Apple processor. The test setup, including other assumptions, is described in detail in research articles [Forsell22, Forsell23].
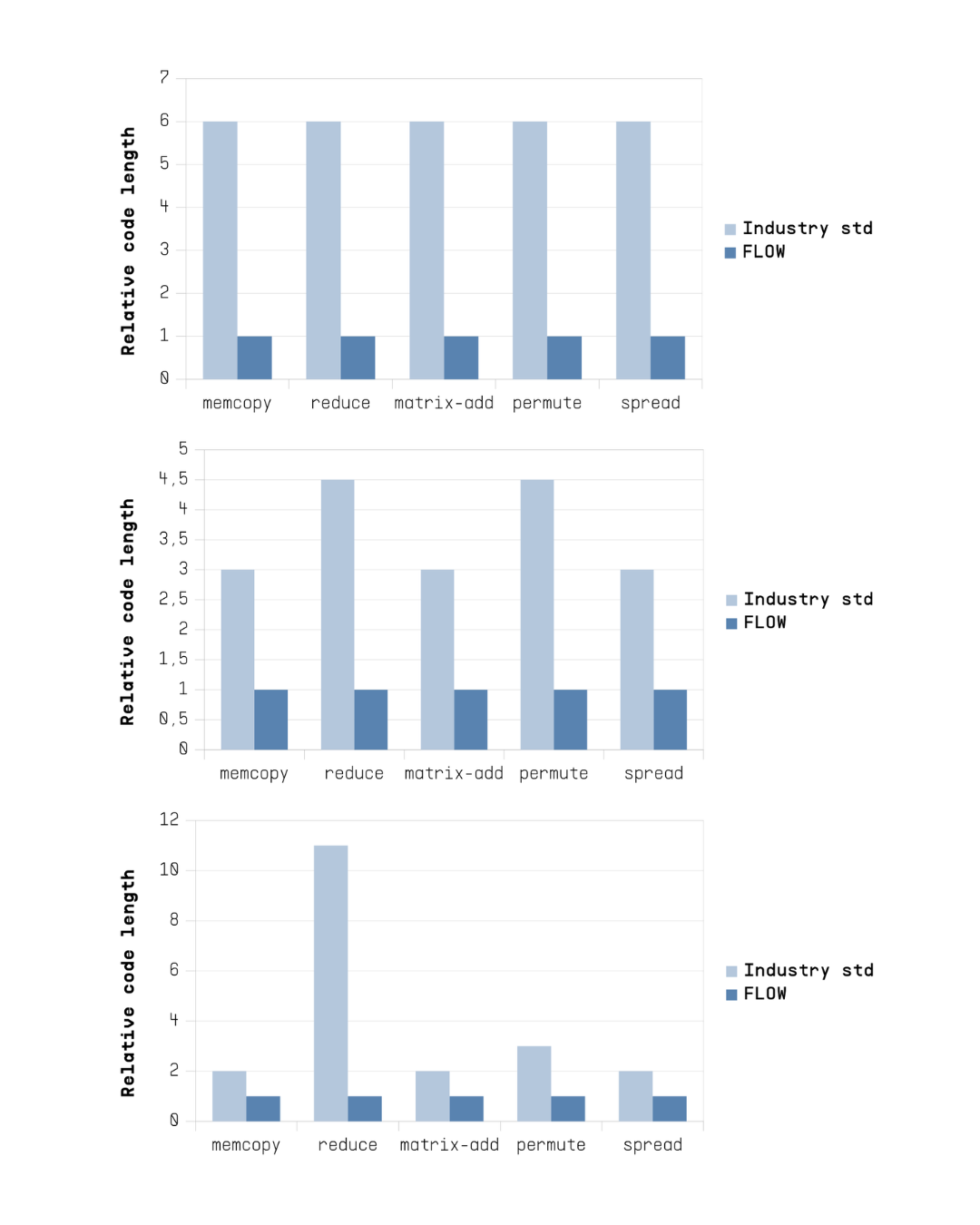
Flow achieves 50-85% code reduction, improving productivity and maintainability.
Parallel programming on current CPUs is often complex due to architectural weaknesses that force programmers to use inefficient ways to write algorithms. This has a negative effect on software engineering productivity for parallel workloads. Programming in Flow's systems is simple due to the architecture optimized for efficient parallel computing. In order to figure out what is the practical difference between Flow and the current CPUs, the number of active program lines was determined for the compute pattern tests for included algorithm styles (maximally parallel, matched parallel and blocking).
Based on the measurements, Flow-based implementations required 50-85% fewer lines of active code than comparable Pthreads programs on Apple’s M-series, not counting Pthreads thread management routines. The highest code size reductions for Flow were achieved against the blocking code variants performing the best on Apple's M-series. In the tested workloads, Flow’s implicit handling of synchronization and insensitivity to memory partitioning enables higher performance with less code lines and potentially fewer bugs.
All in all, Flow’s programming model streamlines the coding of parallel functionalities and allows software teams to proceed faster without sacrificing performance [Forsell22]. This translates to measurable improvements in engineering efficiency, reduced development effort, and a lower cognitive burden when delivering high-performance parallel software.
Near-linear scaling in parallel
Flow breaks through the scaling limitations of SMP and NUMA-based architectures [Forsell22, Culler99].
Our architecture scales nearly linearly in performance and bandwidth as core counts increase in contrast to the sublinear scalability observed on Apple M-series CPUs with maximally parallel (Figure above top), matched parallel (Figure above middle upper) and blocking (Figure above middle lower) Pthreads versions. Expected speedups would have been 2.0x when migrating from M1 to M1 Max and 4.24x when moving from M1 to M4 Max but the measured results ranged from 0.84x to 1.0x for M1 Max and from 1.53x to 2.45x for M4 Max.
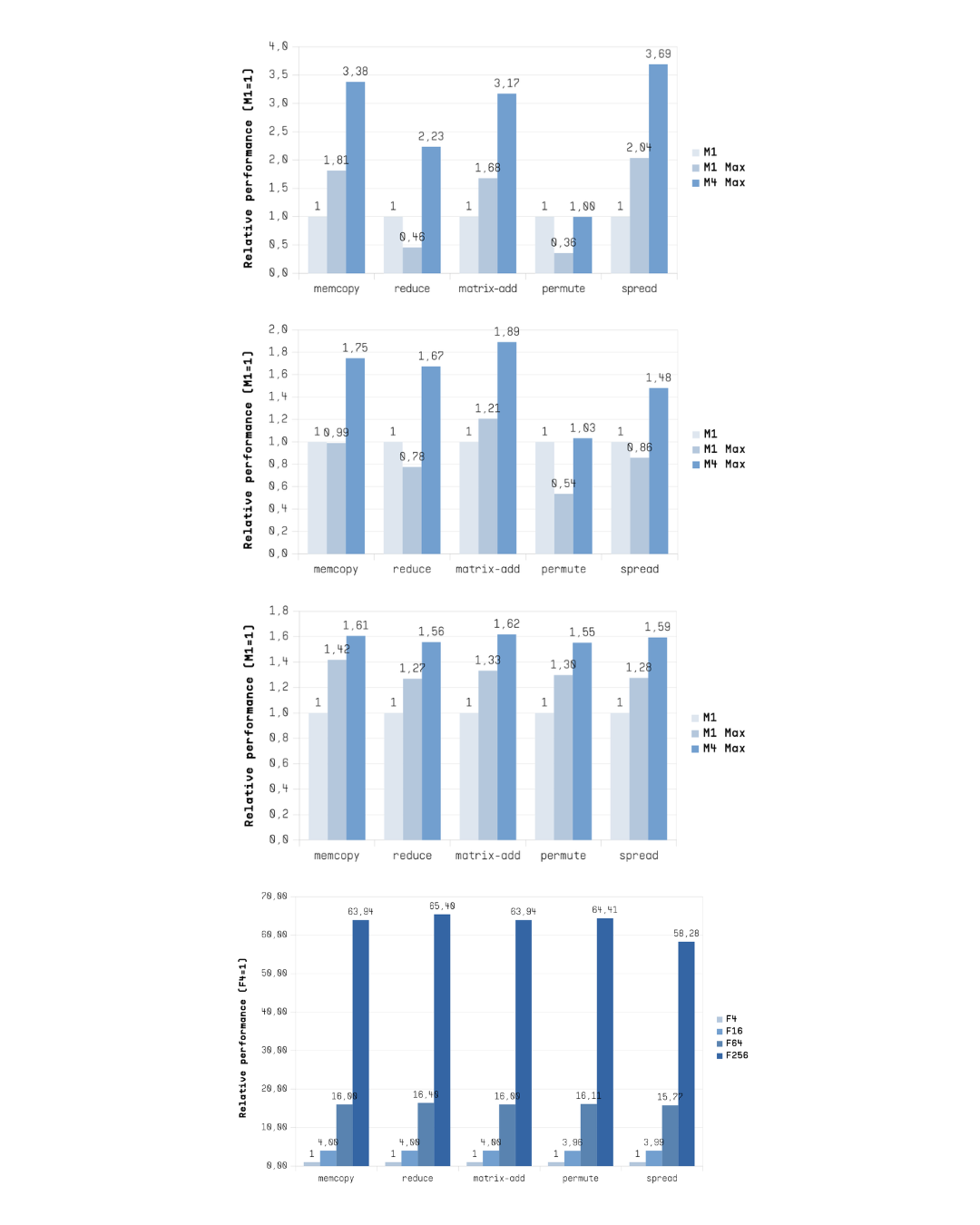
The latency of barrier synchronization in our architecture is just one clock cycle and stays the same as core counts increase in contrast to the sublinear scalability observed on Apple M-series CPUs.
References
Curious to dive deeper into the research behind Flow’s PPU?
About the author
Martti Forsell, Ph.D., Docent, is the CTO and Chief Architect of Flow Computing, co-founded alongside Jussi Roivainen and Timo Valtonen.
Before Flow
Forsell served as a researcher, Assistant, Senior Assistant and Interim Professor at the University of Joensuu, Finland as well as a Principal Scientist at VTT Technical Research Centre of Finland, where he focused on advanced computing architectures and parallel processing.
He is the inventor of the Parallel Processing Unit (PPU).
A groundbreaking technology designed to enhance CPU performance significantly. With over 160 scientific publications, over 100 scientific presentations, more than 2700 citations and more than 9000 accesses to the J. Supercomputing article on the performance and programmability of TCF processors, Dr. Forsell has significantly contributed to the fields of computer architecture and parallel computing. His expertise and innovative work continue to drive advancements in high-performance computing.
Curious about Flow’s performance? Let’s talk.
c