The Flow Parallel Processing Unit® solves one of computing's most fundamental dilemmas: parallel processing.
Core benefits of Flow Computing®'s technology
Speed is the superpower of computing
The innovative Flow Parallel Processing Unit (PPU) enhances CPU performance significantly, ushering in the next generation of CPU performance.
Designed for full backward compatibility, Flow PPU boosts the performance of existing software and applications after recompilation. The more parallel the functionality, the greater the boost in performance.
Flow's technology even enhances the entire computing ecosystem. While the CPU gains direct benefits, ancillary components (matrix units, vector units, NPUs, and GPUs) also see improved performance through the boosted CPU capabilities, all thanks to the PPU.
Significantly faster legacy software and applications
Flow PPU enhances legacy code without altering the original application and delivers greater performance gains when paired with recompiled operating system or programming system libraries.
The result? Significant improvements across a wide range of applications, especially those that exhibit parallelism but are constrained by traditional thread-based processing. Flow PPU unlocks the full potential of these applications, delivering significant performance gains where previous architectures fell short.
Parametric design
The configurable, parametric design of Flow PPU allows it to adapt to diverse uses. Everything can be tailored to meet specific requirements of multiple use cases. And we do mean everything. The number of PPU cores and the type and number of functional units, such as ALUs, FPUs, MUs, GUs, and NUs. Even the size of on-chip memory resources, caches, buffers, and scratchpads can be tailored to suit specific requirements.
The performance scalability is directly linked to the number of PPU cores. A Flow PPU with 4 cores is ideal for small devices like smartwatches, a 16-core Flow PPU is perfect for smartphones, and a 64-core Flow PPU delivers excellent performance for PCs. For servers, a Flow PPU with 256 cores is recommended, enabling them to handle the most demanding computing tasks with ease.
/ PPU
What is Flow Parallel Processing Unit?
Flow Parallel Processing Unit (PPU) is an IP block that integrates tightly with the CPU on the same silicon. It is designed to be highly configurable to meet specific requirements of numerous use cases.
Customization options include:
- Number of cores in the Flow PPU
- Type and number of functional units (such as ALUs, FPUs, MUs, GUs, NUs)
- Size of on-chip memory resources (caches, buffers, scratchpads)
- Instruction set modifications tailored to complement the CPU’s instruction set extensions
CPU modifications are minimal, involving the integration of the PPU interface into the instruction set and an update to the number of CPU cores to unlock new levels of performance.
Our parametric design enables extensive customization, including the number of Flow PPU cores, the variety and number of functional units, and the size of on-chip memory resources. Your performance enhancement scales with the number of Flow PPU cores. A 16-core Flow PPU is ideal for small devices like smartwatches; a 64-core PPU is well-suited for smartphones and PCs; and a 256-core PPU excels in high-demand environments such as AI, cloud, and edge computing servers.
How is this boost possible?
Here's how Flow PPU solves the challenges around CPU latency, synchronization, and virtual-level parallelism. Our innovative and patented technologies are implemented in Flow PPU, and together they will make significant performance boosts a reality.
1. Latency hiding
CURRENT MULTICORE CPU: Memory access, and especially shared access, represent a big challenge for multicore CPUs. Memory references slow down execution, the intercore communication network causes additional latency. Traditional cache hierarchies cause coherency and scalability problems.
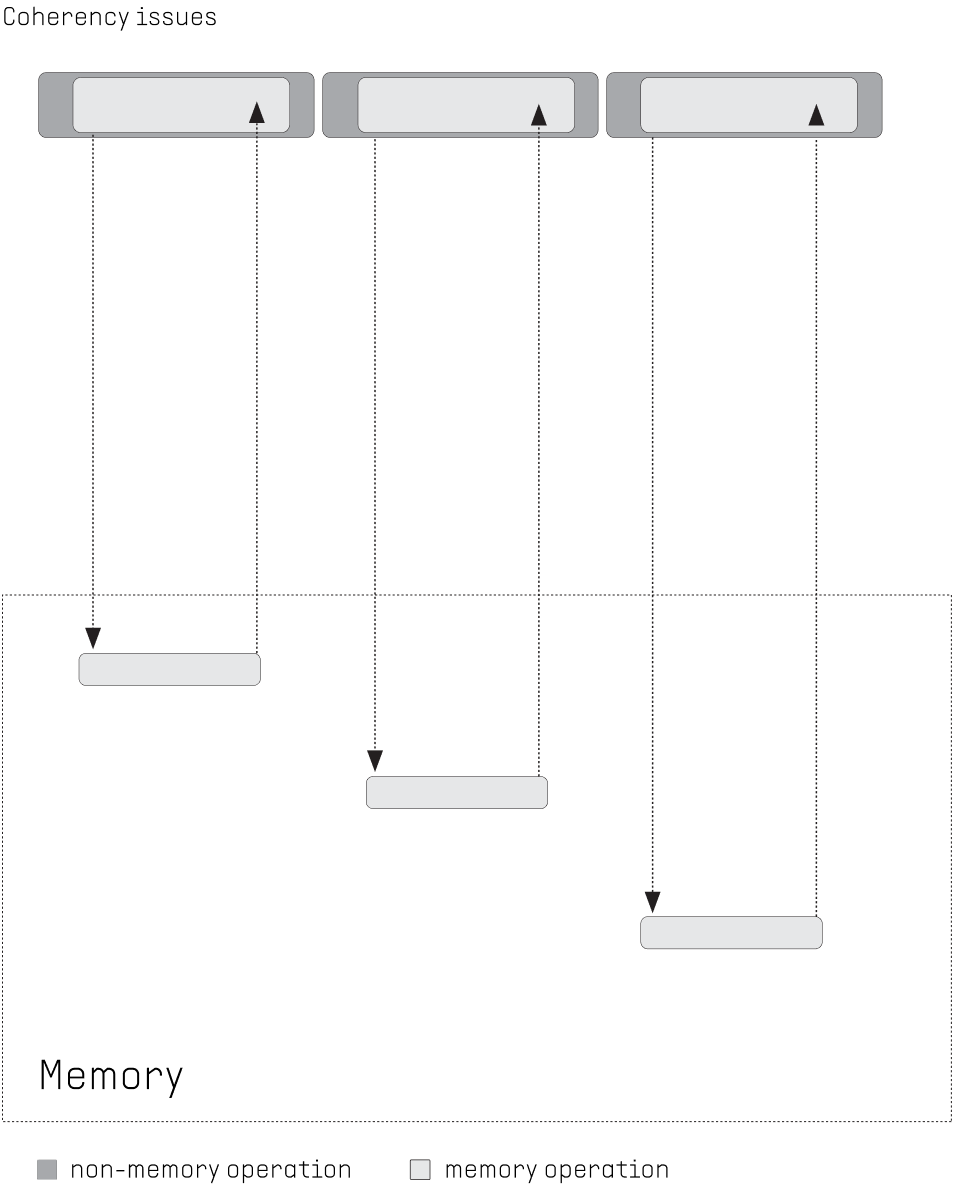
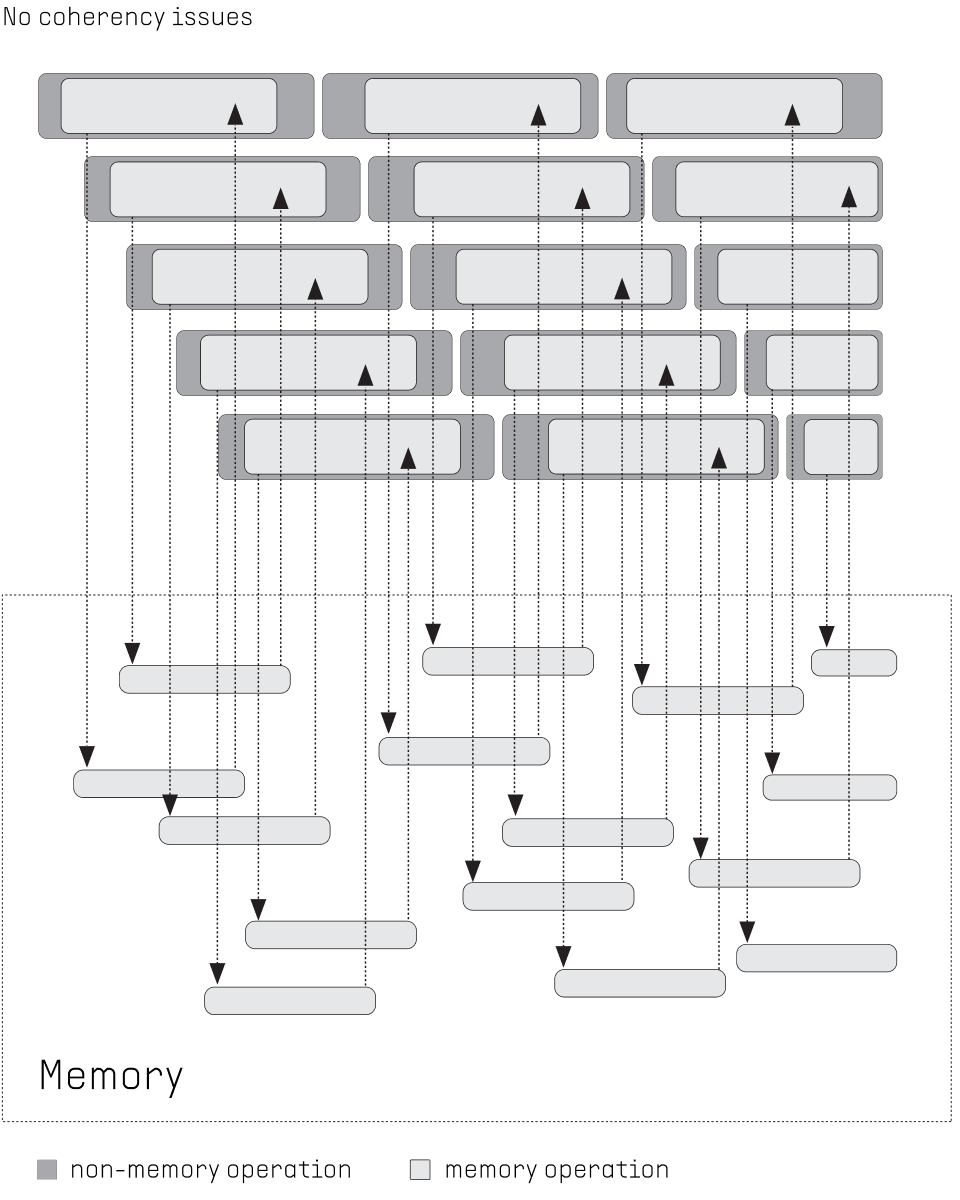
FLOW PPU: Latency of memory references is hidden by executing other threads while accessing the memory. No coherency problems since no caches are placed at the front of the network. Scalability is provided via a high-bandwidth network-on-chip.
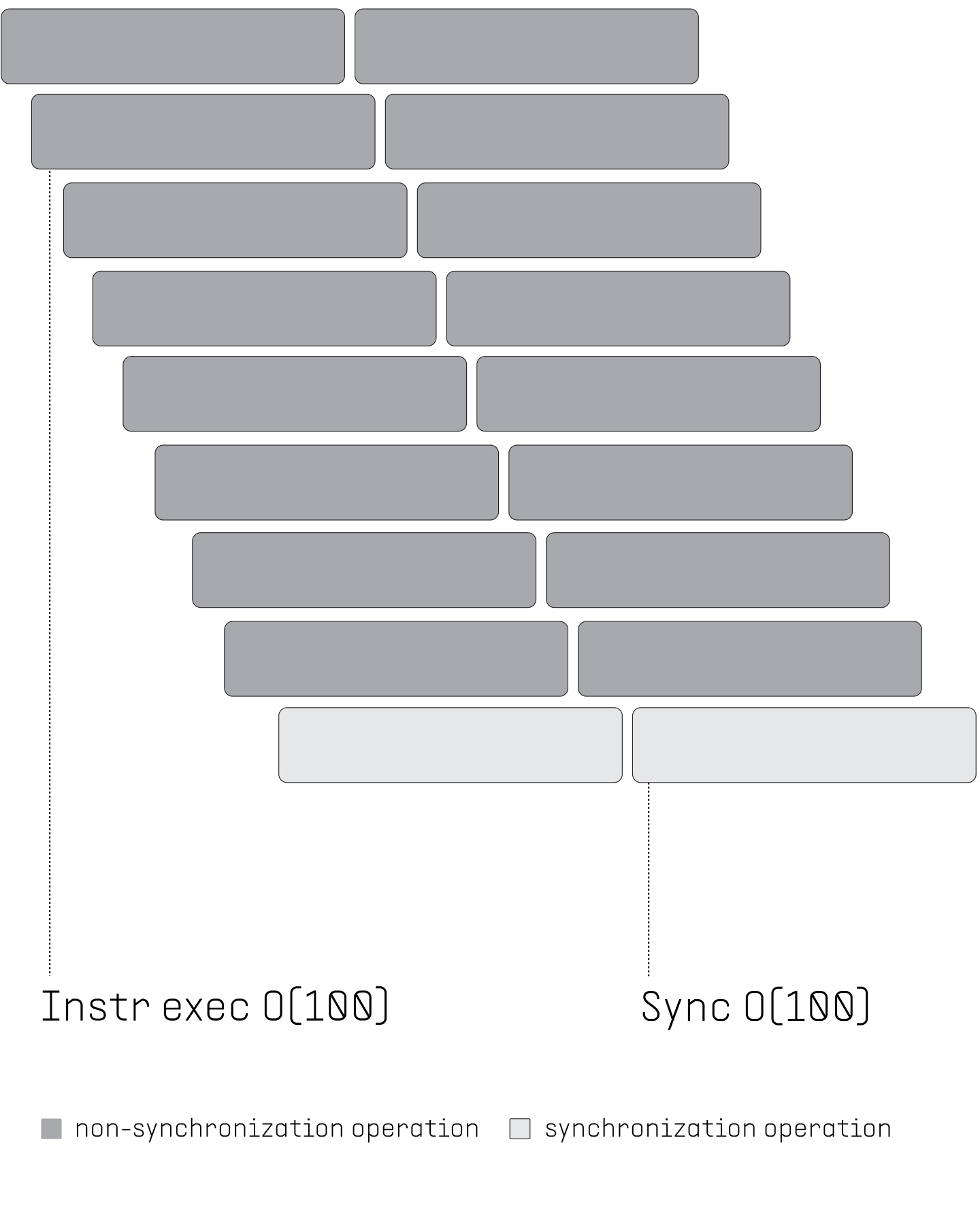
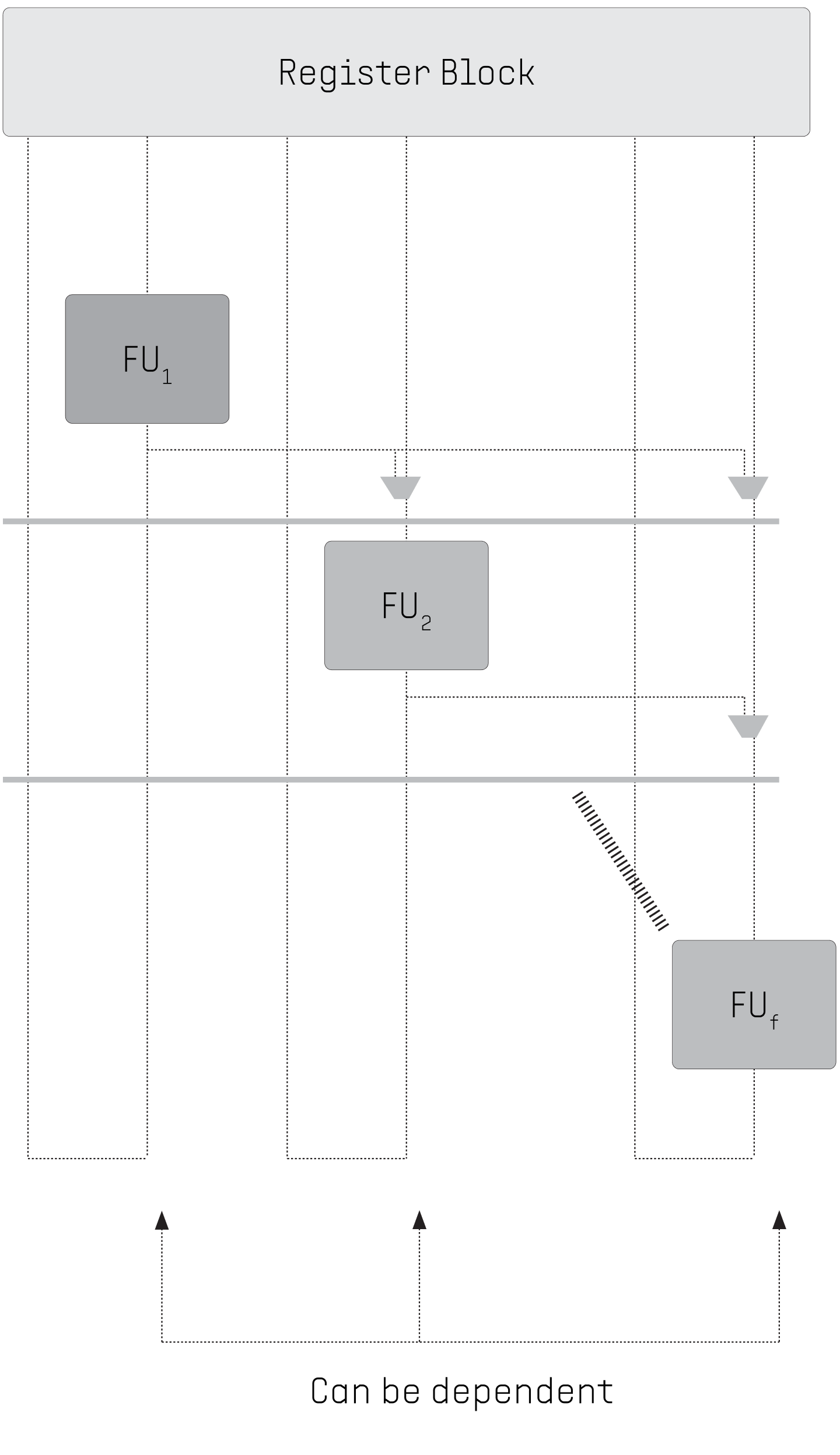
2. Synchronization
CURRENT MULTICORE CPU: Usage of parallelism causes additional challenges. Due to the inherent asynchrony of the CPU's processor cores, synchronization of threads is required whenever there are inter-thread dependencies. These synchronizations are very expensive (taking 100 to 1000 clock cycles).

FLOW PPU: Synchronizations are needed only once per step since the threads are independent of each other within a step (dropping the cost down to 1). Synchronizations are overlapped with the execution (dropping the cost down to 1/100).
3. VIRTUAL ILP/LLP
CURRENT MULTICORE CPU: Suboptimal handling of low-level parallelism. Multiple instructions can be executed in multiple functional units only if instructions are independent. Pipeline hazards slow down instruction execution.
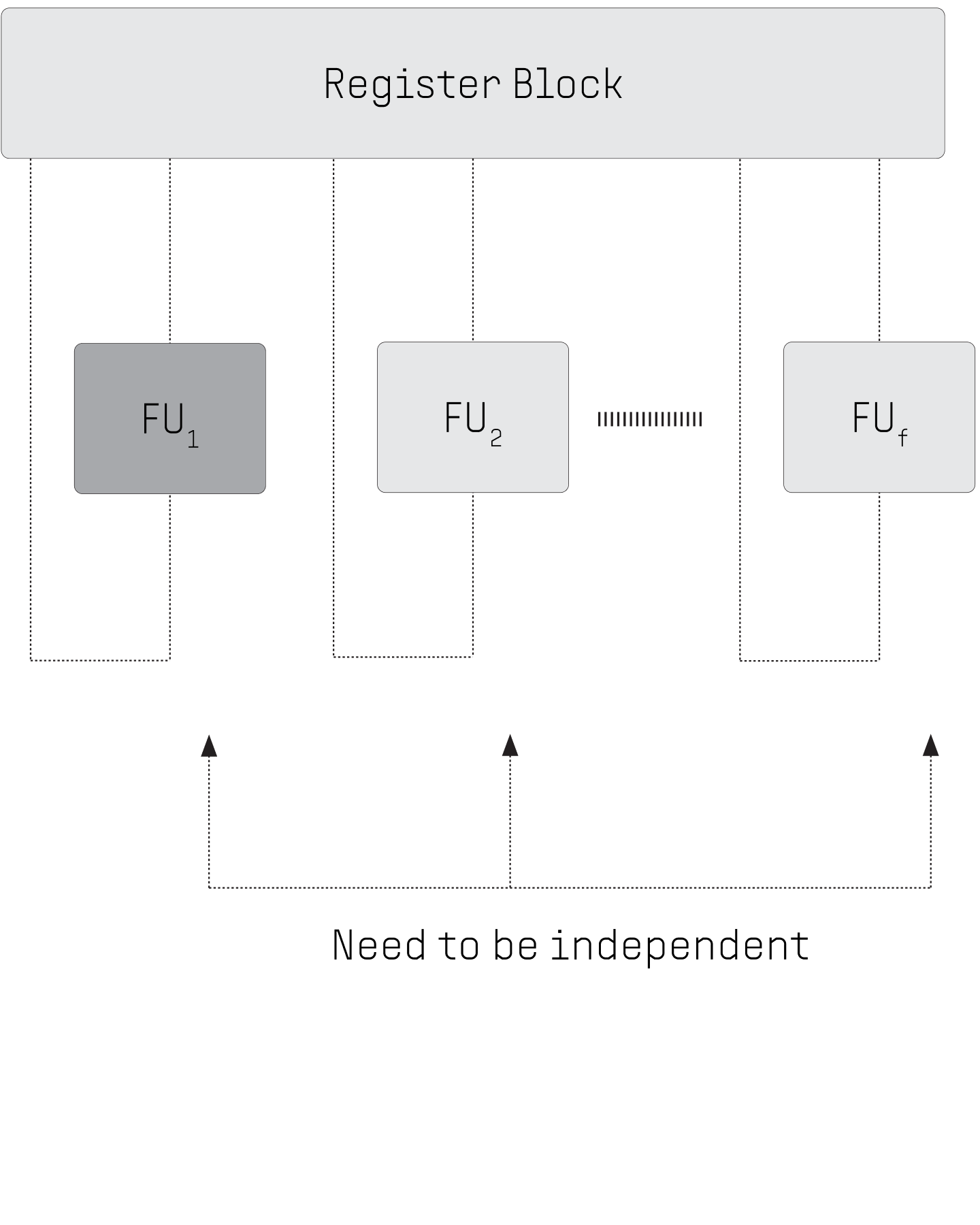
FLOW PPU: Functional units are organized as a chain where a unit can use the results of its predecessors as operands. Dependent code execution is possible within a step of execution. Pipeline hazards are eliminated.
Performance boost for existing software & applications
Our technology is fully backward compatible with all existing legacy software and applications. Flow PPU's compiler automatically recognizes parallel parts of the code and executes those in Flow PPU cores.
What’s more, we are developing an AI tool to help application and software developers identify parallel parts of the code and to propose methods of streamlining those for maximum performance.

Why better CPU performance is vital for future industries?
“While our investments in compute accelerators have transformed our customers’ capabilities, general-purpose compute is and will remain a critical portion of our customers’ workloads. Analytics, information retrieval, and ML training and serving all require a huge amount of compute power. Customers and users who wish to maximize performance, reduce infrastructure costs, and meet sustainability goals have found that the rate of CPU improvements has slowed recently. Amdahl’s Law suggests that as accelerators continue to improve, general purpose compute will dominate the cost and limit the capability of our infrastructure unless we make commensurate investments to keep up.”
Extract from Google announcement of its first Arm-based CPU on April 9th, 2024

Artificial intelligence
General purpose computing is and will remain a critical portion of numerous AI workloads. Analytics, information retrieval, and ML training and serving all require massive amounts of computing power.
All parties wishing to maximize performance, reduce infrastructure costs, and meet sustainability goals have run into a slowing rate of CPU improvement. Unless CPUs can keep up, general purpose computing will limit the capability and dominate the cost of AI.

Autonomous vehicle systems
While we may not be manufacturing autonomous flying cars, the intricate technology behind such innovations requires immense parallel processing power. Exactly what the next generation CPUs enhanced by Flow PPU are designed to provide. They deliver the robust performance necessary for the high-speed, real-time data processing that autonomous vehicle systems demand.
Moreover, our technology excels in edge computing environments where low latency is critical, ensuring that decision-making processes are as swift as they are reliable. By integrating Flow PPU, autonomous systems gain the capability to react instantaneously to dynamic conditions, enhancing safety and efficiency.

New opportunities
Emerging fields such as simulation and optimization, widely used in business computing from logistics planning to investment forecasting, will greatly profit from Flow. Such applications tend to be heavily parallelized, and will greatly benefit from the flexibility of Flow technology over GPU thread blocks.
Flow technology also works for the classic numeric and non-numeric parallelizable workloads, from matrix or vector computations to sorting. Even in code with only small parallelizable parts, which are currently not parallelized because runtime overhead is larger than runtime benefit, Flow PPU will nonetheless boost the overall performance.